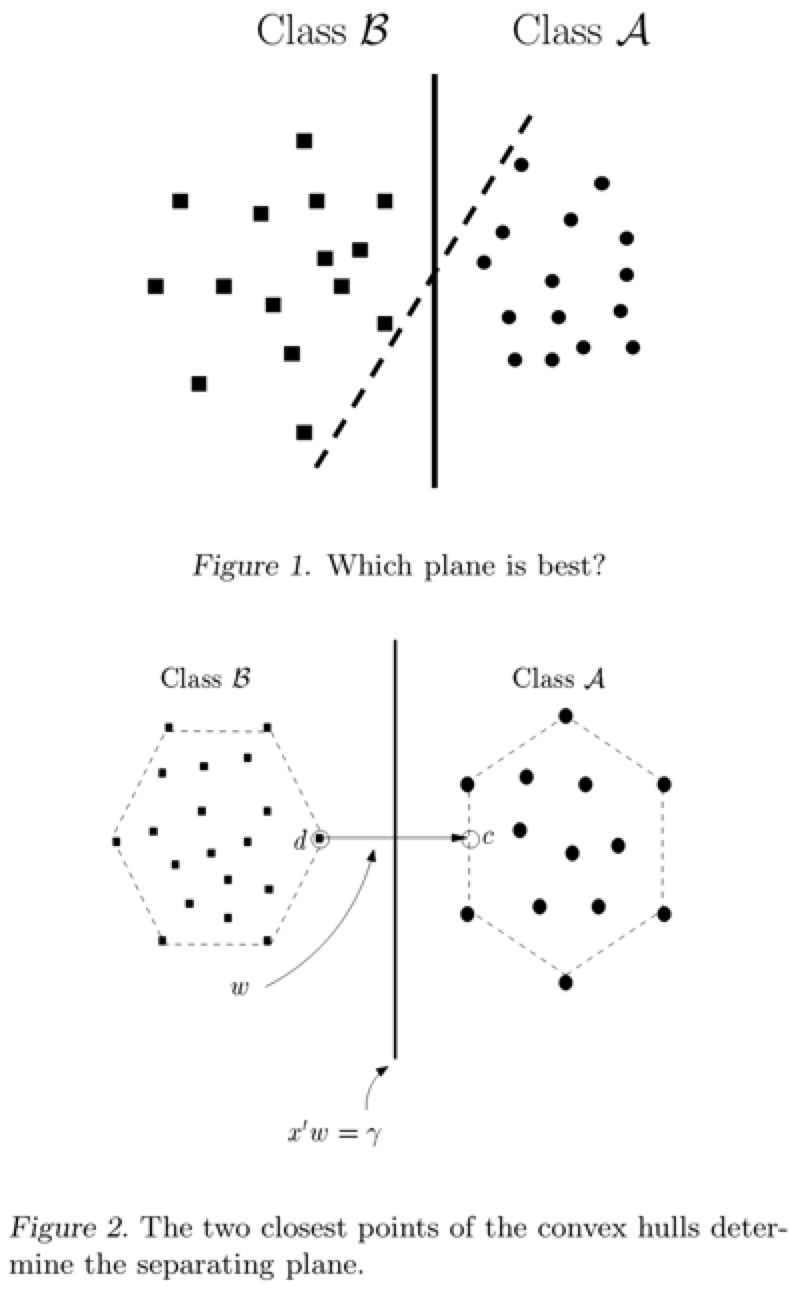
Support Vector Machines (SVM) is a supervised learning algorithm used for classification, regression, and outlier detection. Support vector machines focus only on the points that are the most difficult to tell apart, whereas other classifiers pay attention to all of the points.
The intuition is that if a classifier is good at separating the most challenging points (that are close to each other), then it will be even better at separating other points. SVM searches for the closest points, so-called “support vectors” (the points are like vectors and the best line “depends on” or is “supported by” them).
Then SVM draws a line connecting these points. The best separating line is perpendicular to it.
Mathematical Formulation
For a binary classification problem:
Linear SVM: Minimize: 21∣∣w∣∣2 Subject to: yi(w⋅xi+b)≥1 for all i
Soft Margin SVM (allowing some misclassifications): Minimize: 21∣∣w∣∣2+C∑i=1nξi Subject to: yi(w⋅xi+b)≥1−ξi and ξi≥0 for all i.
SVM optimization problem can be rewritten as 21∣∣w∣∣2+C∗Σmax(0,1−yi(w⋅xi+b)) - the sum of hinge losses for all training examples.
Where:
w is the normal vector to the hyperplane
b is the bias
C is the regularization parameter
ξi are slack variables
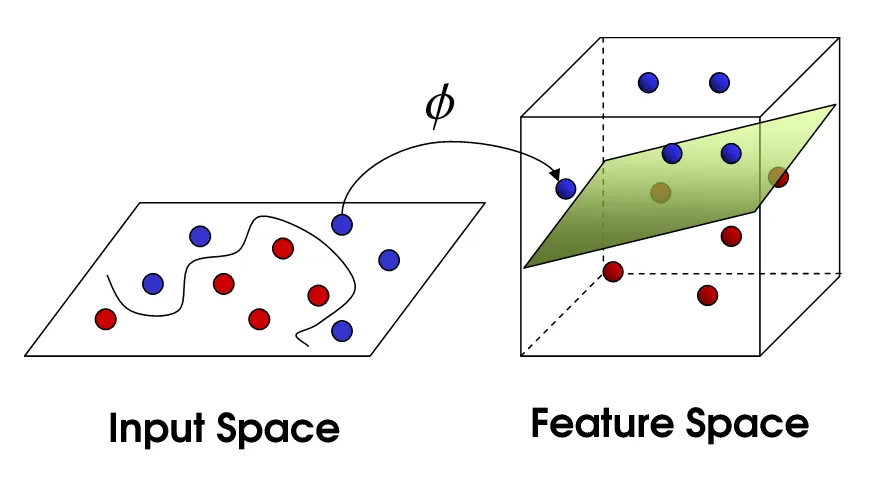
Kernel Trick
The idea is that the data, that isn’t linearly separable in the given n dimensional space may be linearly separable in a higher dimensional space.
The kernel trick provides a solution. The “trick” is that kernel methods represent the data only through a set of pairwise similarity comparisons between the original data observations x (with the original coordinates in the lower dimensional space), instead of explicitly applying the transformations ϕ(x) and representing the data by these transformed coordinates in the higher dimensional feature space.
In kernel methods, the data set X is represented by an n⋅n kernel matrix of pairwise similarity comparisons where the entries (i,j) are defined by the kernel function: k(xi,xj). This kernel function has a special mathematical property. The kernel function acts as a modified dot product.
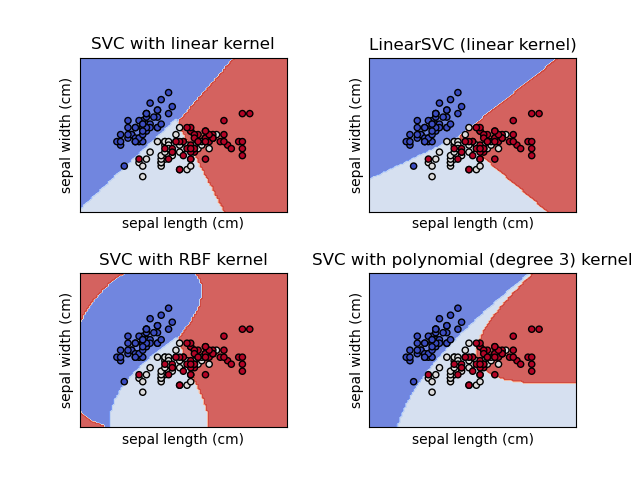
Linear: K(xi,xj)=xi⋅xj
Polynomial: K(xi,xj)=(γxi⋅xj+r)d
RBF (Gaussian): K(xi,xj)=exp(−γ∣∣xi−xj∣∣2)
Sigmoid: K(xi,xj)=tanh(γxi⋅xj+r)
Advantages
Effective in high-dimensional spaces
Memory efficient as it uses only support vectors
Versatile through different kernel functions
Robust against overfitting
Disadvantages
Sensitive to the choice of kernel and regularization parameter
Does not directly provide probability estimates (requires additional methods like Platt Scaling, significantly increases computation cost)
Can be computationally intensive for large datasets