K-means is an unsupervised machine learning algorithm used for partitioning a dataset into K distinct, non-overlapping subgroups (clusters). It uses Clustering metrics for evaluation.
Not to be confused with knn. KNN is a supervised algorithm for classification/regression finding nearest neighbors, K-means is an unsupervised algorithm for clustering finding cluster centroids.
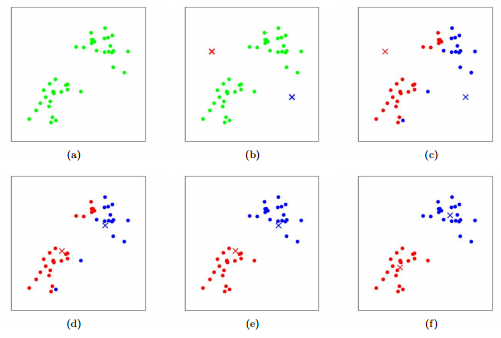
How It Works
Choose the number K of clusters
Initialize K centroids randomly
Repeat until convergence:
Assign each data point to the nearest centroid
Update the centroids by calculating the mean of all points assigned to that centroid
The algorithm has converged when the assignments no longer change
Initialization: μ1,μ2,...,μK∈Rn
Assignment Step: c(i):=argminj∣∣x(i)−μj∣∣2
Update Step: μj:=∑i=1m1c(i)=j∑i=1m1c(i)=jx(i)
Where:
μj is the centroid for cluster j
c(i) is the cluster assignment for data point i
x(i) is the i-th data point
Distance Metrics
Typically uses Euclidean distance: d(x,y)=∑i=1n(xi−yi)2
Choosing K
Elbow Method: Plot the within-cluster sum of squares (WCSS) against K and look for the “elbow”
Silhouette Analysis: Measure how similar an object is to its own cluster compared to other clusters
Gap Statistic: Compare the total within intra-cluster variation for different values of k with their expected values under null reference distribution of the data
Advantages
Simple
Scales well to large datasets
Guarantees convergence
Can warm-start with known centroids if available
Disadvantages
Needs to specify K beforehand
Sensitive to initial centroid placement
Sensitive to outliers
Variations
K-means++
K-means++ helps the convergence by improving initialization. It selects initial cluster centroids using sampling based on an empirical probability distribution of the points’ contribution to the overall inertia.
Mini-batch K-means (K-means with buckets)
Instead of using the entire dataset in each iteration, Mini-Batch K-means uses small, random batches of data. The process repeats until convergence or a maximum number of iterations is reached.
Code example
> import numpy as npclass KMeans: def __init__(self, k=3, max_iters=100): self.k = k self.max_iters = max_iters def kmeans_plus_plus(self, X): centroids = [X[np.random.randint(X.shape[0])]] for _ in range(1, self.k): distances = np.min([np.sum((X - c) ** 2, axis=1) for c in centroids], axis=0) probabilities = distances / distances.sum() cumulative_probabilities = probabilities.cumsum() r = np.random.rand() for j, p in enumerate(cumulative_probabilities): if r < p: centroids.append(X[j]) break return np.array(centroids) def fit(self, X): # Randomly initialize centroids self.centroids = X[np.random.choice(X.shape[0], self.k, replace=False)] # Or use K-means++ initialization self.centroids = self.kmeans_plus_plus(X) for _ in range(self.max_iters): # Assign points to closest centroid distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2)) labels = np.argmin(distances, axis=0) # Update centroids new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.k)]) # Check for convergence if np.all(self.centroids == new_centroids): break self.centroids = new_centroids return labels def predict(self, X): distances = np.sqrt(((X - self.centroids[:, np.newaxis])**2).sum(axis=2)) return np.argmin(distances, axis=0)