Regularization is a technique used in machine learning to prevent overfitting by adding a penalty term to the loss function. It discourages learning a more complex or flexible model, to favor a simpler, more generalizable one.
Regularization refers to a set of techniques used in machine learning to prevent overfitting and improve the generalization of models. A common way of applying regularization is adding a penalty term to the loss function, but there are many other methods, some of which are model-agnostic. In general, regularization aims to:
- Prevent overfitting
- Improve model generalization
- Handle multicollinearity in regression problems
- Feature selection (in case of L1 regularization)
Common types of regularization
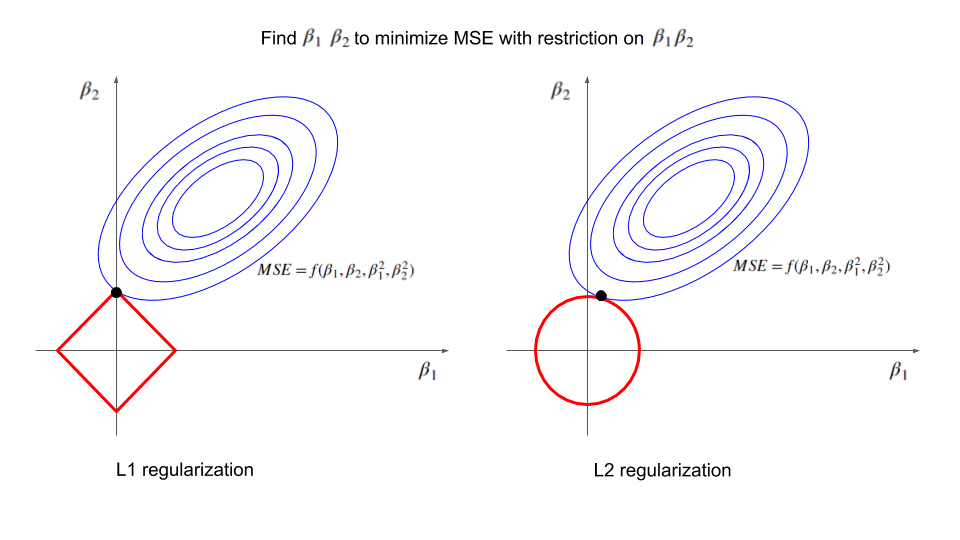
L1 Regularization (Lasso)
- Adds the sum of absolute values of coefficients to the loss function:
- Tends to produce sparse models and thus can be used for feature selection
- Can shrink coefficients to exactly zero
L2 Regularization (Ridge)
- Adds the sum of squared values of coefficients to the loss function:
- Shrinks all coefficients
- Handles multicollinearity well
Elastic Net
- Combination of L1 and L2 regularization:
- Balances the benefits of L1 and L2
- Tends to select groups of correlated variables together, unlike Lasso, which may arbitrarily select one
Model-specific types of regularization
- L1, L2, Elastic net in linear models
- Pruning and decreasing complexity in tree-based models
- C parameter (inverse of regularization strength) in Support Vector Machines
Model-agnostic types of regularization
- Early stopping: stops training when performance on a validation set starts to degrade
- Data Augmentation: artificially increases the size of the training set by generating new changed samples
- Noise injection: adds random noise to inputs or weights during training
Neural-net specific types of regularization
- Dropout: randomly drops a number of output units during training
- Weight decay (L2): adds a penalty term to the loss function proportional to the sum of squared weights
- Batch normalization: normalizes the input of each layer across the batch, reduces internal covariate shift
- Layer normalization: normalizes the input of each layer across the features
- Label Smoothing: replaces hard labels with soft probabilities
- Gradient Clipping: limits the size of the gradients during backpropagation
- Stochastic Depth: randomly drops entire layers during training
Be careful with using too many types of regularization blindly
There are cases when different types of regularization have unexpected interactions.
Weight Decay (L2) and Batch Normalization: when used together with BN an L2 penalty no longer has its original regularizing effect. Instead, it becomes essentially equivalent to an adaptive adjustment of the learning rate! Source
Dropout and Batch Normalization: use BN before Dropout, not after. Link to the discussion.