Wide & Deep Learning is a joint model architecture developed by Google for recommendation systems and search ranking. It combines a linear (wide) model with a deep neural network to achieve both memorization and generalization.
- Memorization: Learning the frequent co-occurrence of items or features to capture direct, explicit relationships in historical data
- Generalization: Transferring learned patterns to new item combinations and exploring new feature combinations
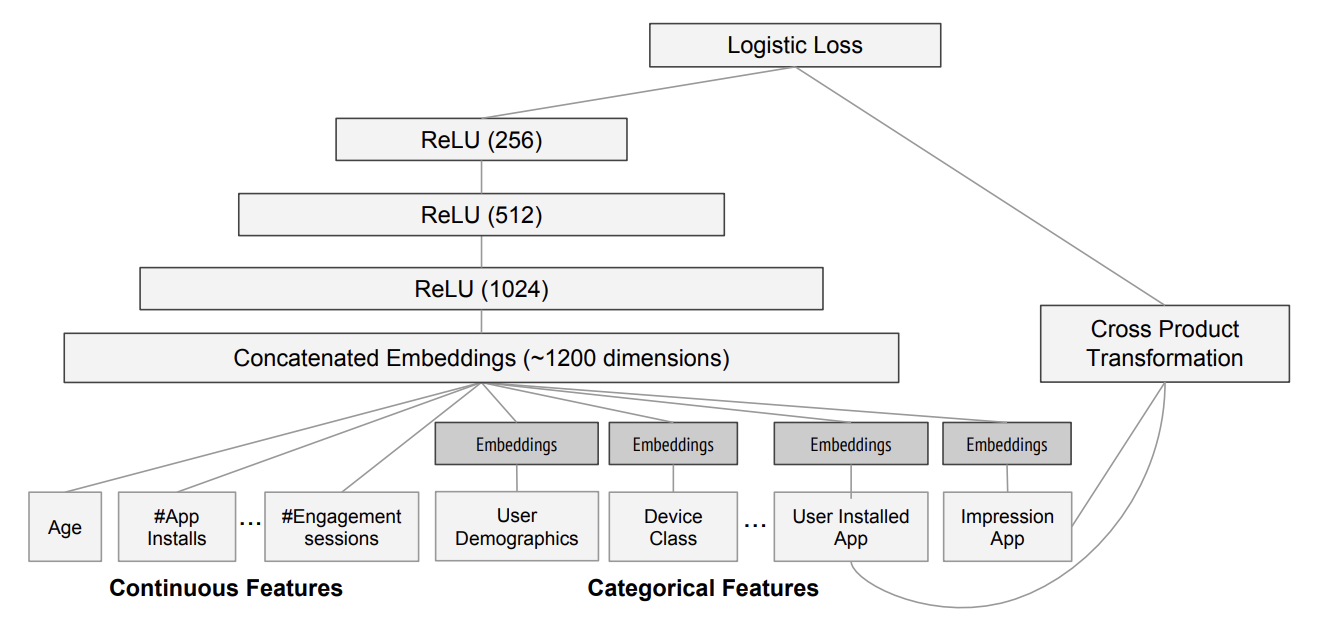
Architecture
- Wide component: A linear model that uses features, one-hot encoded categorical features and feature combinations (concatenating values of categorical features)
- Deep component: A feed-forward neural network that takes dense embeddings or numerical features as input. Often consists of multiple fully connected layers with activation functions (ReLU).
- Joint Training: The outputs from the wide component and the deep component are combined with a weighted sum into a final prediction.
- Trained end-to-end with a single loss function (logistic loss for classification, regression for numeric predictions).
Advantages
- Combines memorization abilities of linear models with generalization capabilities of deep networks
- Better handles both sparse and dense features
- Scalable
- Flexible feature engineering
Disadvantages
- Still requires some manual feature engineering for the wide component
- Training can be computationally intensive, may overfit
Possible improvements
- DeepFM: Combines Factorization Machines with deep networks, replacing the wide component
- Deep & Cross Network: Uses explicit feature crossing layers instead of manual feature engineering