[Paper](https://ai.meta.com/research/publications/sam-3-segment-anything-with-concepts/)
[Blogpost](https://ai.meta.com/blog/segment-anything-model-3/)
[Demo](https://aidemos.meta.com/segment-anything)
[Code and weights](https://github.com/facebookresearch/sam3)
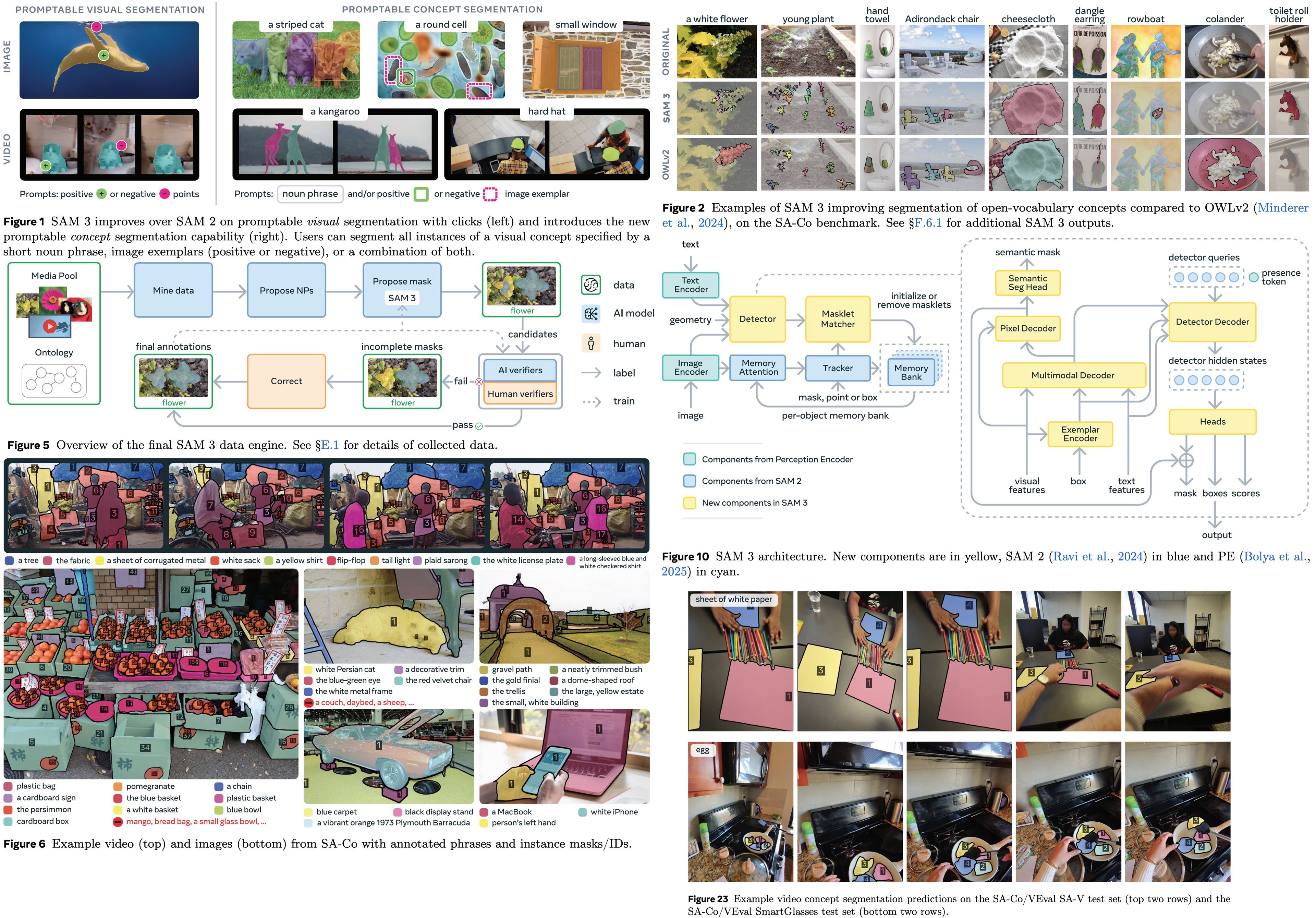
SAM 3 is a new, unified model that can detect, segment, and track objects in both images and videos using concept prompts — short text descriptions ("yellow school bus"), example images, or both. It uses a new task called Promptable Concept Segmentation (PCS), where the model finds and masks all objects that match the prompt, giving each a consistent ID across frames.
To make this work, the authors built a huge high-quality dataset with 4 million concept labels, including hard negatives, for both images and videos. The model itself combines an image detector and a video tracker built on a shared backbone and introduces a separate "presence head" that helps it decide whether a concept is present before localizing it.
SAM 3 significantly improves accuracy and outperforms older SAM models on visual segmentation tasks.
### Promptable Concept Segmentation
Promptable Concept Segmentation is a task where, given an image or a short video (up to 30 seconds), the model must detect, segment, and track all instances of a visual concept defined by a prompt. Text prompts apply to the whole video, while exemplar prompts can be added on specific frames (positive or negative boxes) to refine results—useful when the model misses objects or the concept is rare.
All prompts must refer to the same concept; mixing mismatched prompts (e.g., 'fish' + 'just the tail') leads to undefined behavior.
Because PCS allows any visually groundable noun phrase, the task is inherently ambiguous: polysemy ('mouse'), subjective terms ('cozy'), vague/ungroundable concepts, and boundary uncertainty. To handle this, the authors collect annotations from multiple experts, adapt evaluation to allow multiple valid interpretations, refine annotation guidelines to reduce ambiguity, and include a dedicated ambiguity module in the model.
### Model
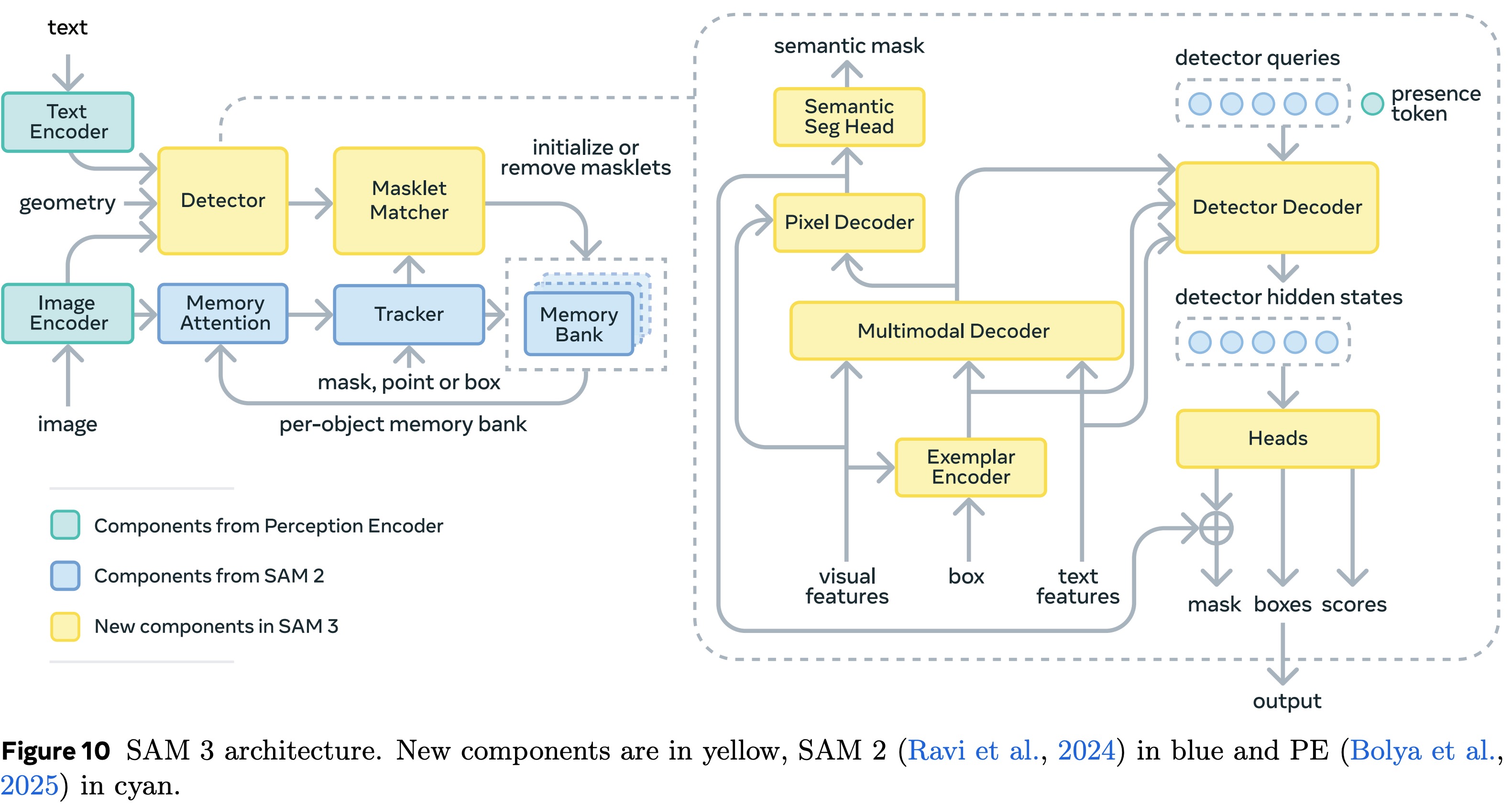
SAM 3 generalizes SAM 2 by supporting the new PCS task alongside earlier point-based visual segmentation. It uses text prompts, image exemplars, or visual prompts to define which objects to detect, segment, and track across an image or an entire video. Prompts can be added interactively to fix missed or incorrectly detected instances.
#### Detector (image-level)
The detector is based on [[End-to-End Object Detection with Transformers|DETR]]:
* Encodes the image, text prompts, and image exemplars.
* Fuses them through cross-attention.
* Uses object queries to output box predictions and classification (whether each object matches the prompt).
* Includes a mask head (MaskFormer-style) and a semantic segmentation head.
A learned global **presence token** predicts whether the prompted concept is present in the frame.
**Image Exemplars** are bounding boxes with positive/negative labels that help the model understand what the user means. For example, given a positive bounding box on a dog, the model will find all dogs in the image (unlike SAM 1 and 2).
#### Video Tracking
SAM 3 adds a memory-based tracker, sharing the same backbone as the detector.
* Detector finds new objects on each frame.
* Tracker propagates masklets (object-specific spatio-temporal masks) from the previous frame.
* Matching step merges tracked objects with new detections.
* New masklets are created when new objects appear.
To handle ambiguity, the masklets get a temporal detection score; unreliable ones are suppressed. The tracker periodically re-prompts itself with high-confidence detection masks to recover from drift, occlusion, or confusion in crowded scenes. The tracker predicts three candidate masks per object and picks the most confident one to handle uncertainty.
At any point, the user can refine a mask or masklet using positive/negative clicks. The refined mask is then propagated across the whole video.
### Data Engine
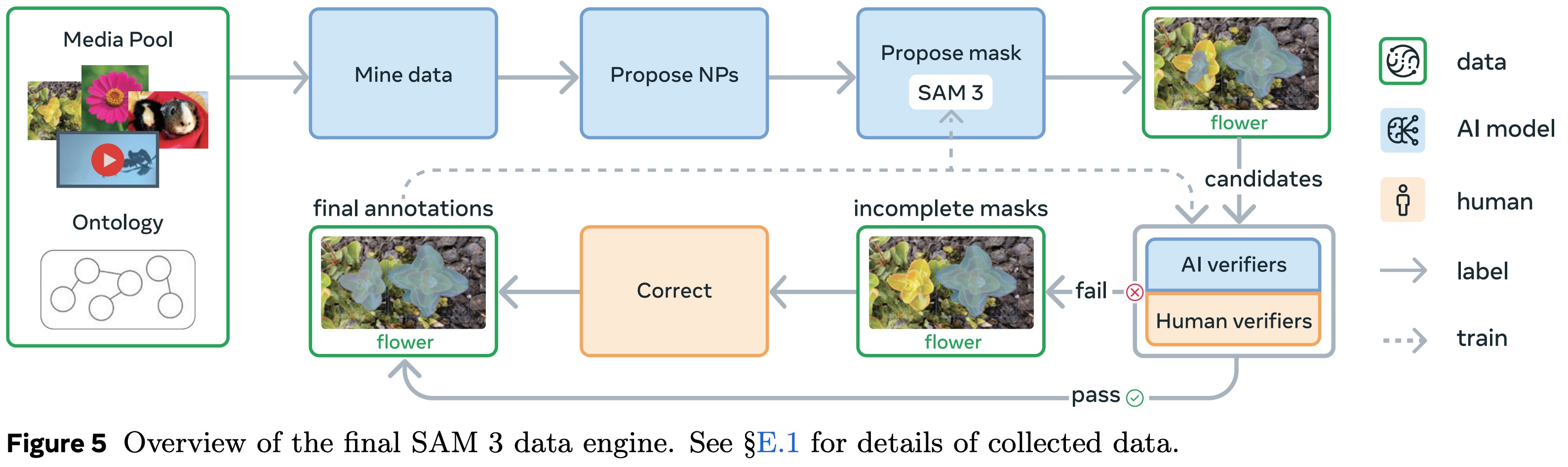
SAM 3 achieves its large jump in performance by training on a massive, diverse set of concepts. To build this data, the team created an iterative data engine where media are mined from large pools, noun phrases are proposed by AI models, and SAM 3 generates initial masks. These masks then go through a two-stage verification process: first checking their quality and relevance, and then checking whether all instances of the concept were captured. Any failures are corrected manually, with annotators adding or editing masks or discarding unclear phrases.

The data engine was developed in four phases. The first phase relies entirely on humans, using SAM 2 and simple captioning models to propose concepts and collect 4.3 million image–phrase pairs. In the second phase, AI verifiers trained on human labels take over mask and exhaustivity checks, doubling throughput and adding 122 million more pairs. The third phase expands coverage across fifteen visual domains and adds fine-grained, long-tail concepts sourced from alt-text and a large ontology, resulting in 19.5 million more pairs. The final phase extends to videos, using a mature SAM 3 to generate spatio-temporal masklets, filtering difficult clips, and collecting a dataset of 52.5k videos and 467k masklets focused on crowded scenes and tracking challenges.
### Experiments
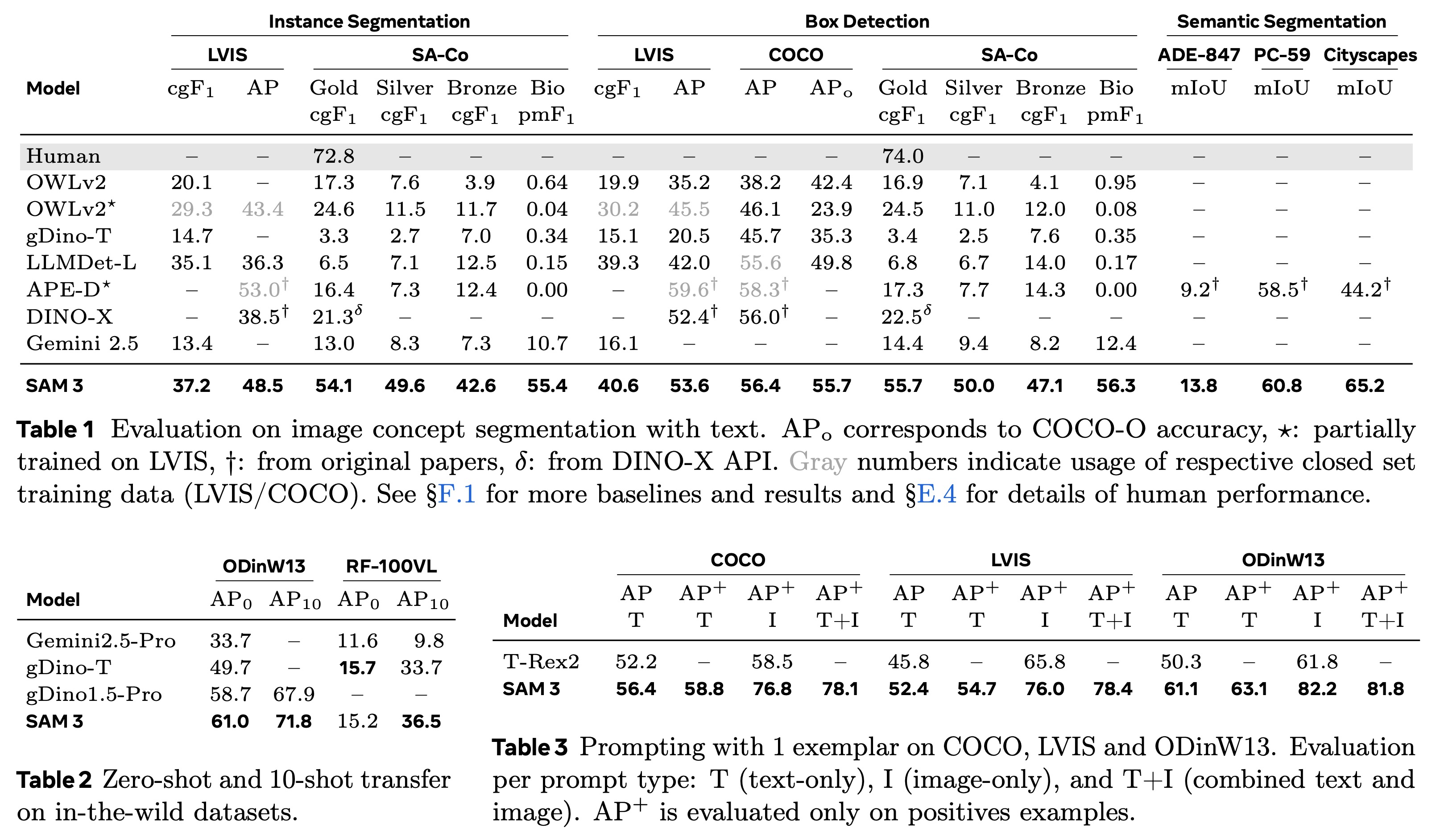
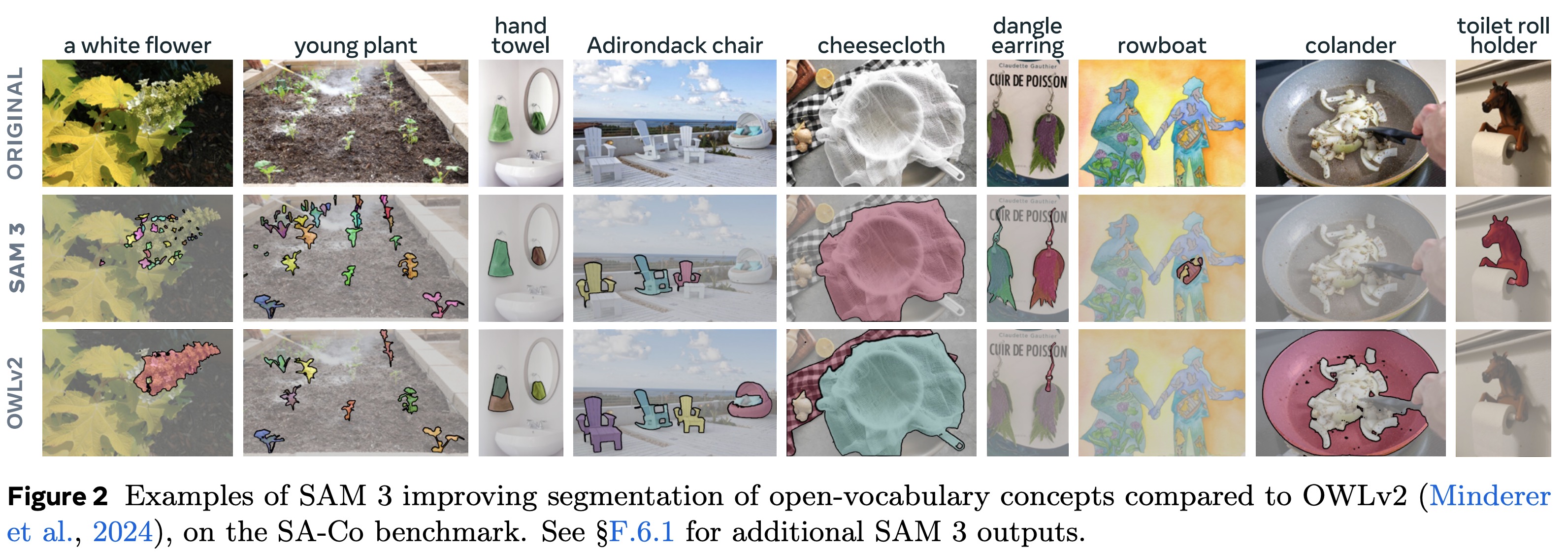
SAM 3 is evaluated across image segmentation, video segmentation, few-shot detection, counting, and interactive refinement. With only a text prompt, it achieves state-of-the-art results on COCO, LVIS, COCO-O, and open-vocabulary benchmarks, more than doubling the performance of strong baselines on SA-Co/Gold. It also outperforms specialist models in open-vocabulary semantic segmentation.
In few-shot adaptation, SAM 3 achieves the strongest performance on ODinW13 and RF100-VL, even without prompt tuning, and surpasses prior detectors and large multimodal models. Using a single exemplar, it improves significantly over T-Rex2, and in interactive settings it quickly boosts accuracy by generalizing from positive and negative examples, outperforming both text-only prompting and SAM-style point-based refinement.
For counting tasks, it matches or surpasses multimodal LLMs while providing full segmentation masks. In video segmentation with text prompts, SAM 3 clearly outperforms open-vocabulary video systems and tracking-by-detection baselines, reaching over 80% of human pHOTA on its main benchmark. In standard visual prompting tasks such as video object segmentation and interactive image segmentation, it improves substantially over SAM 2, especially on difficult datasets like MOSEv2.
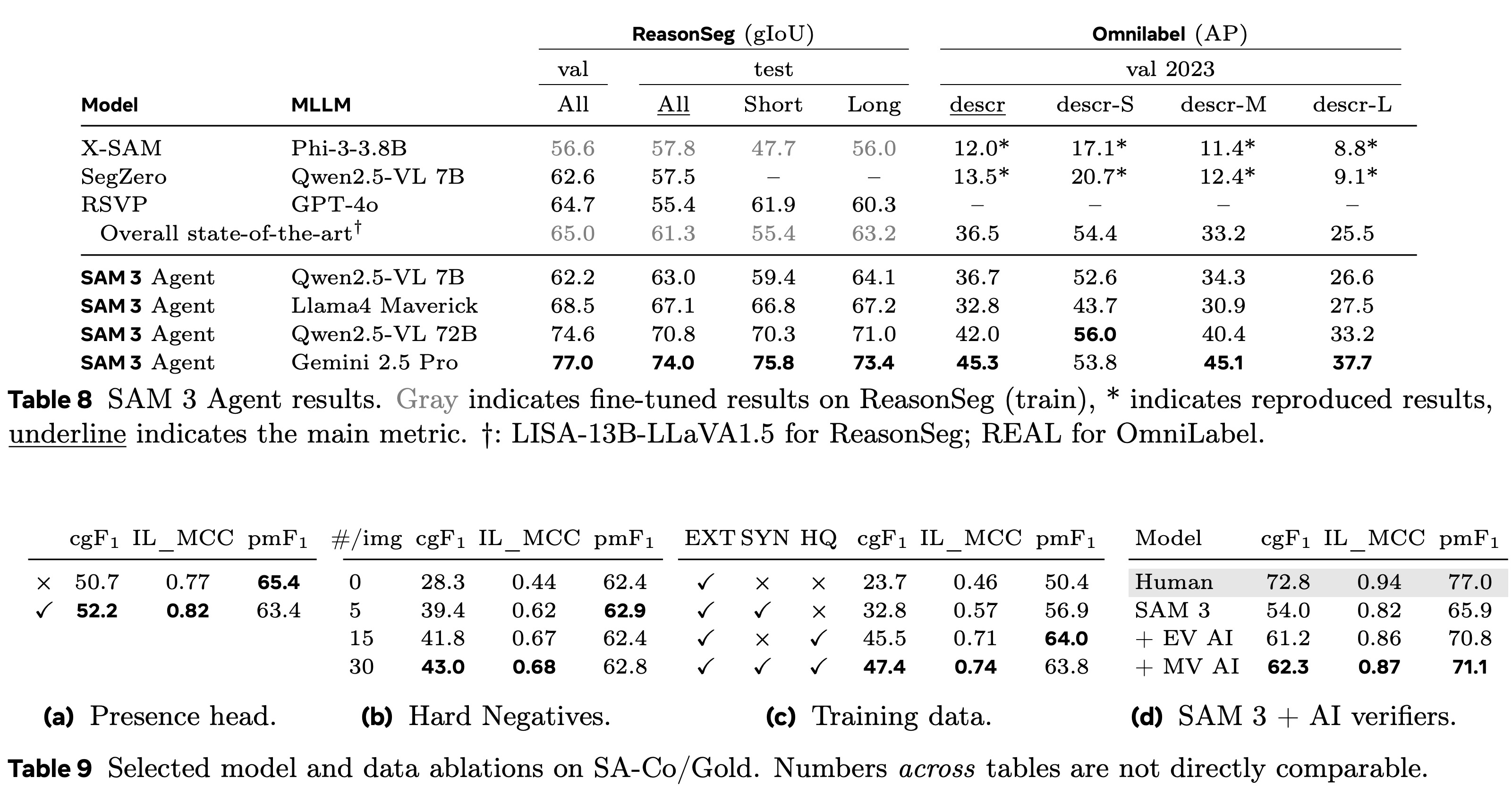
SAM 3 can be paired with an MLLM to form a "SAM 3 Agent", where the language model generates refined noun-phrase prompts, queries SAM 3, inspects the returned masks, and iterates until it gets the correct segmentation. This approach using zero-shot achieves stronger results than previous work on ReasonSeg, OmniLabel, RefCOCO+, and RefCOCOg, and works consistently across different MLLMs without special tuning, showing good robustness.
Ablation studies show several key contributors to performance: the presence head improves recognition and gives a measurable boost to segmentation quality; adding hard negative examples greatly improves image-level understanding; synthetic data and high-quality curated data each add substantial gains, with clear scaling effects; and AI verifiers significantly improve pseudo-labels by replacing weak presence scores and filtering bad masks, closing roughly half the remaining gap to human performance.