[Paper link](https://arxiv.org/abs/2112.02721)
[Code link](https://github.com/GEM-benchmark/NL-Augmenter)

This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
-------
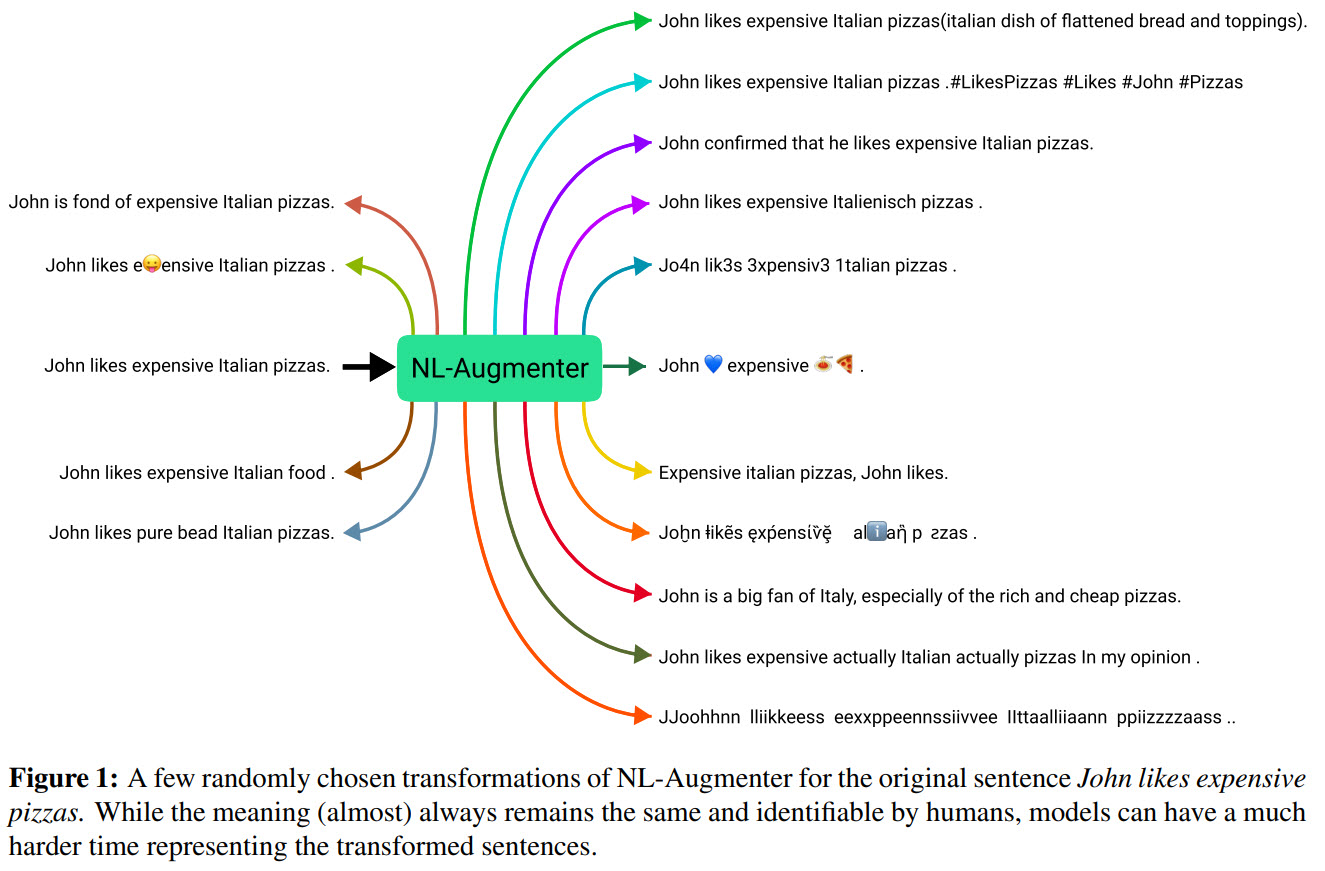
Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of their training data. But most transformations do not alter the structure of examples in drastic and meaningful ways, making them less effective as potential training or test examples.
Some transformations are universally useful, for example, changing places to ones from different geographic regions or changing names to those from different cultures. On the other hand, some NLP tasks may benefit from transforming specific linguistic properties: changing the word “happy” to “very happy” in input is more relevant for sentiment analysis than for summarization.As such, having a single place to collect both task-specific and task-independent augmentations will ease the barrier to creating appropriate suites of augmentations that should be applied to different tasks.
In 2021 several evaluation suites for the [GEM benchmark](https://gem-benchmark.com/) were proposed:
* transformations (e.g. back-translation, introduction of typographical errors, etc.)
* subpopulations, i.e., test subsets filtered according to features such as input complexity, input size, etc.
* data shifts, i.e., new test sets that do not contain any of the original test set material.
NL-Augmenter is a participant-driven repository that aims to enable more diverse and better-characterized data during testing and training. To encourage tasks-specific implementations, transformations are tied to a widely-used data format (e.g., text pair, a question-answer pair, etc.) along with various task types (e.g., entailment, tagging, etc.) that they intend to benefit.
### The organisation of the process

A workshop was organized towards constructing this repository. Unlike a traditional workshop wherein people submit papers, participants were asked to submit python implementations of transformations to the GitHub repository.
The organizers created a base repository and incorporated a set of interfaces. Then, the participants could submit the code following the pre-defined interfaces and it was subjected to the code review: following the style guide, implementing testing and were encouraged to submit novel and/or specific transformations/filters.
At the moment of the paper's publication, there are 117 transformations and 23 filters in the repository.
<div class="gallery" data-columns="2">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-28-23.jpg">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-28-33.jpg">
</div>
## Tags
<div class="gallery" data-columns="3">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-28-42.jpg">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-28-52.jpg">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-29-02.jpg">
</div>
To make searching for specific perturbations and understanding their characteristics easier, three main categories of tags were introduced:
* General properties;
* Output properties;
* Processing properties;
Some of the tags were assigned automatically (from the metadata in the code), others - by the contributors themselves.
## Robustness analysis
All authors of the accepted perturbations were asked to provide the task performance scores for each of their respective transformations or filters.
The perturbations are mainly split into text classification tasks, tagging tasks,
and question-answering tasks. For experiments in this paper, the authors focus on text classification and the relevant perturbations.
They compare the model performance on the original and the perturbed data; the percentage of changed sentenced and the drop in the performance are reported.
Four datasets are used: SST-2 and IMDB for sentiment analysis, QQP for duplicate question detection and MNLI. Their corresponding models (most downloaded on Huggingface) are used for evaluation. A random 20% of the validation dataset is perturbed during the evaluation.
<div class="gallery" data-columns="4">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-40-41.jpg">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-41-15.jpg">
<img src="https://andlukyane.com/images/paper_reviews/nlaugmenter/2021-12-10_13-41-31.jpg">
</div>
## Discussions and impact
Limitations:
* the results show that the tested perturbations introduce serious challenges for the models and decrease their score, but it would be better to analyze the contribution of each separate perturbation;
* some of the perturbations' tags could be inconsistent, and it is necessary to assess the quality of the tag assignment to ensure a reliable analysis;
* the robustness analysis shows the weaknesses of the models, but a separate analysis is necessary to verify that using these perturbations while training will mitigate these weaknesses;
NL-augmenter was created by many participants, and there are risks that the contributions of the individuals will be less appreciated than in standalone projects.
To proactively give appropriate credit, each transformation has a data card mentioning the contributors and all participants are listed as co-authors of this paper.