[Paper link](https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/)
[Code link](https://github.com/facebookresearch/llama)
LLaMA is a collection of large foundation language models, ranging from 7B to 65B parameters, that have been trained on trillions of tokens using publicly available datasets. The LLaMA-13B model outperforms GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
### Pre-training Data
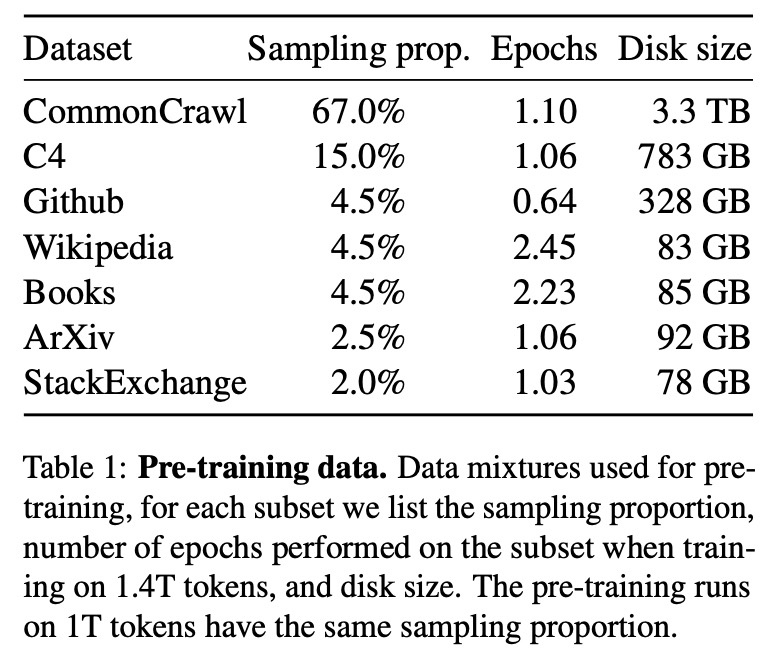
The authors use only publicly available data, so the following datasets are used: English CommonCrawl, C4, Github, Wikipedia, Gutenberg and Books3, ArXiv, Stack Exchange.
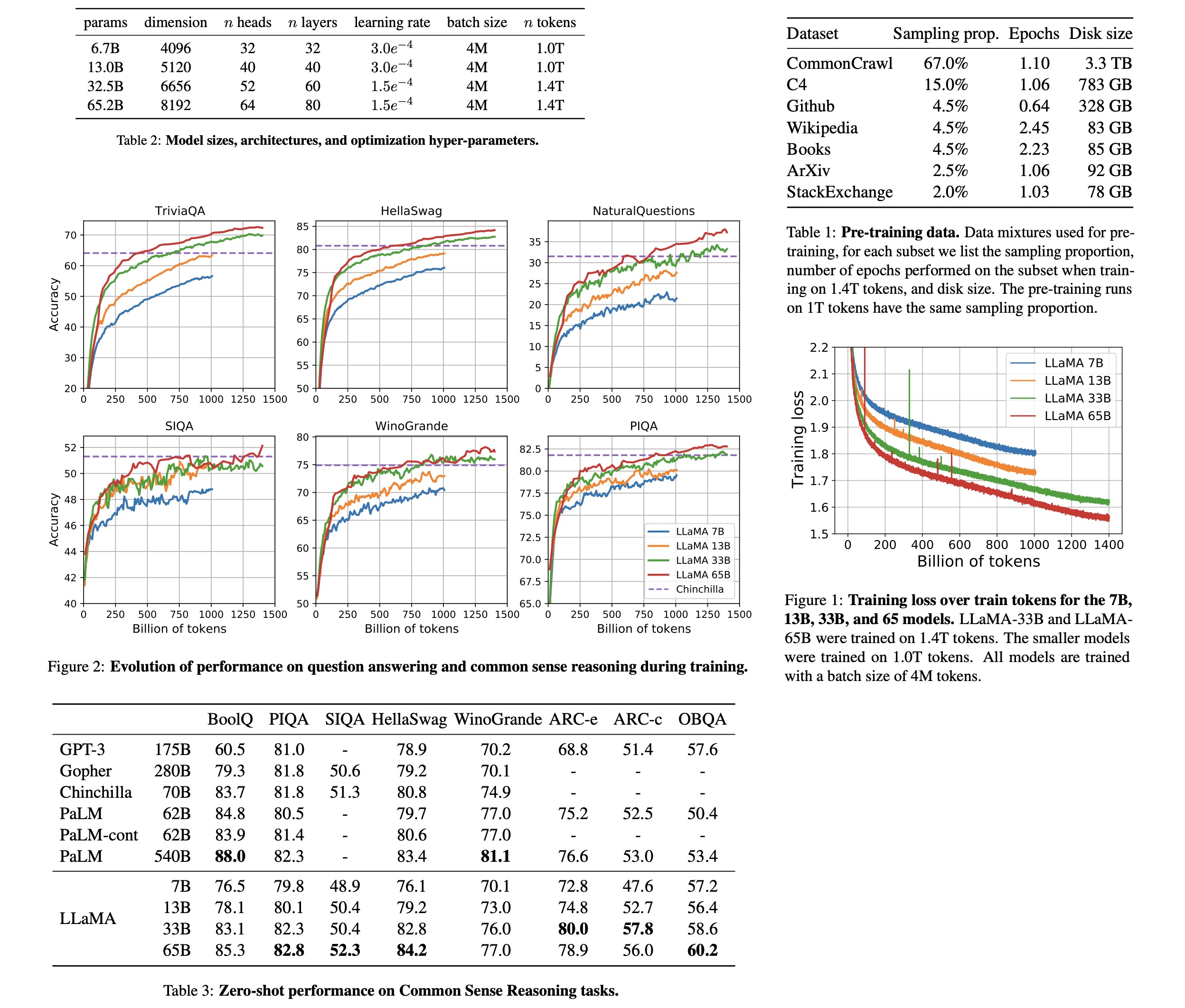
They use BPE as a tokenizer. The whole training dataset has ~1.4T tokens. Most of the tokens are used only once, with the exception of Wikipedia and books, which are used twice.
### Architecture
The authors use the original [[Transformer]] architecture from the paper "Attention is All you Need" with the following changes:
* pre-normalization with RMSNorm instead of output normalization;
* SwiGLU activation function from PaLM. The dimension is `2/3 * 4d` instead of `4d` as in PaLM;
* Rotary Embeddings from GPTNeo instead of positional embeddings
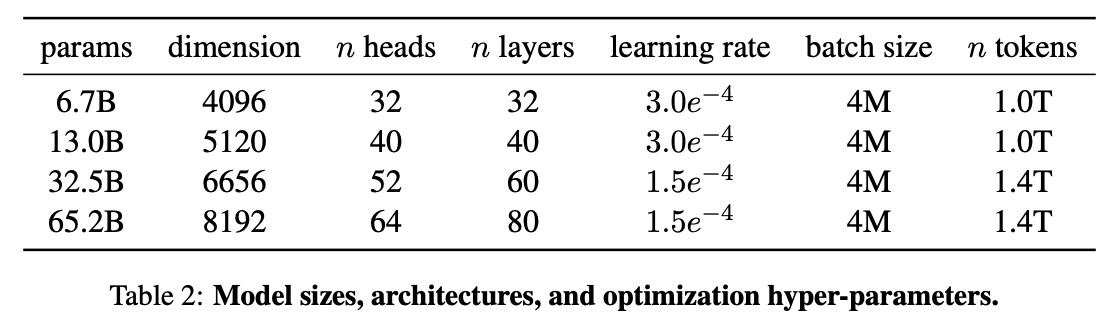
### Training
* AdamW, cosine learning scheduler.
* Efficient implementation of the causal multi-head attention;
* Reducing the number of activations that are recomputed during the backward pass with checkpointing;
They trained the model on 2048 A100 for 21 days.
### Results
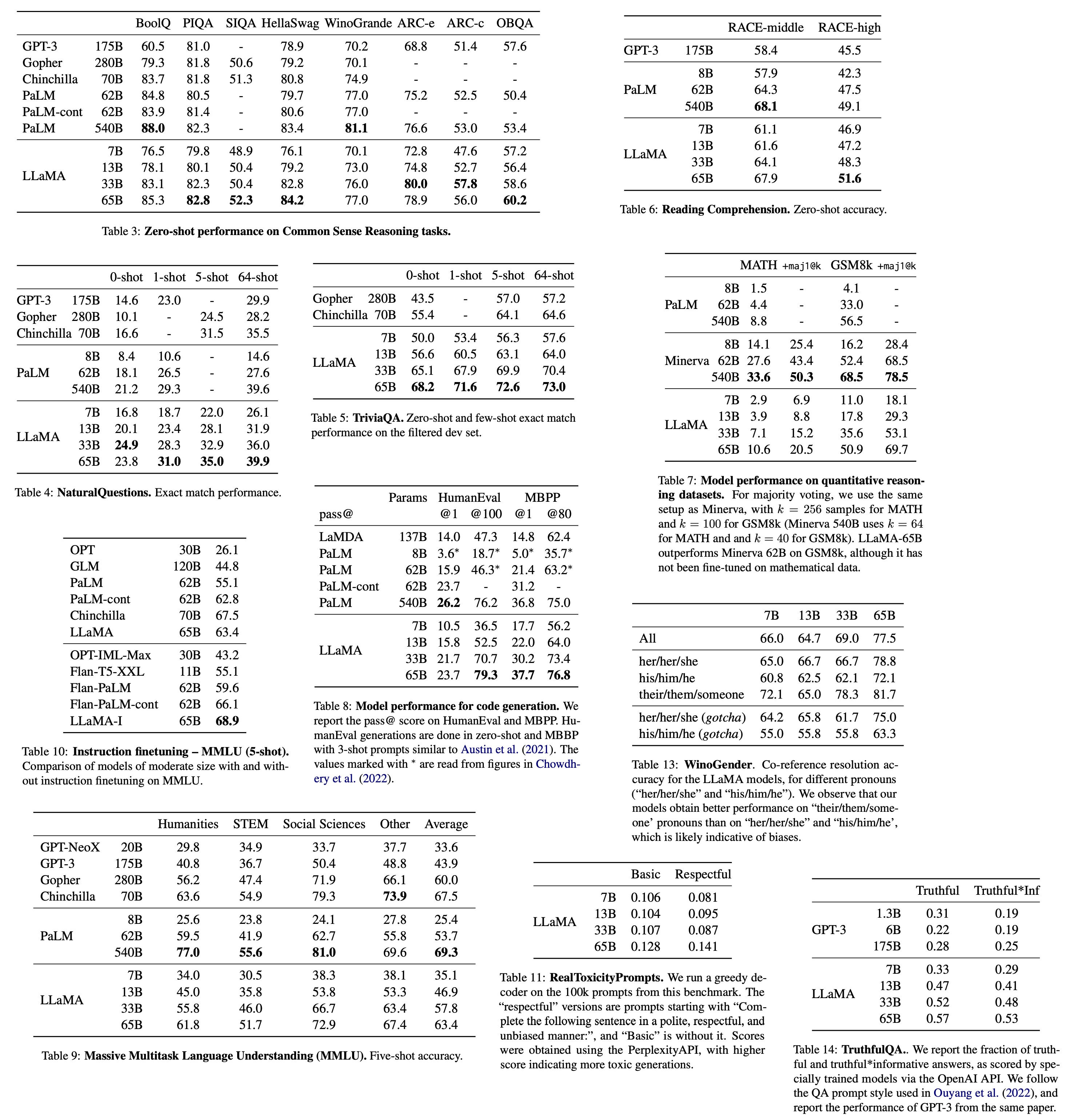
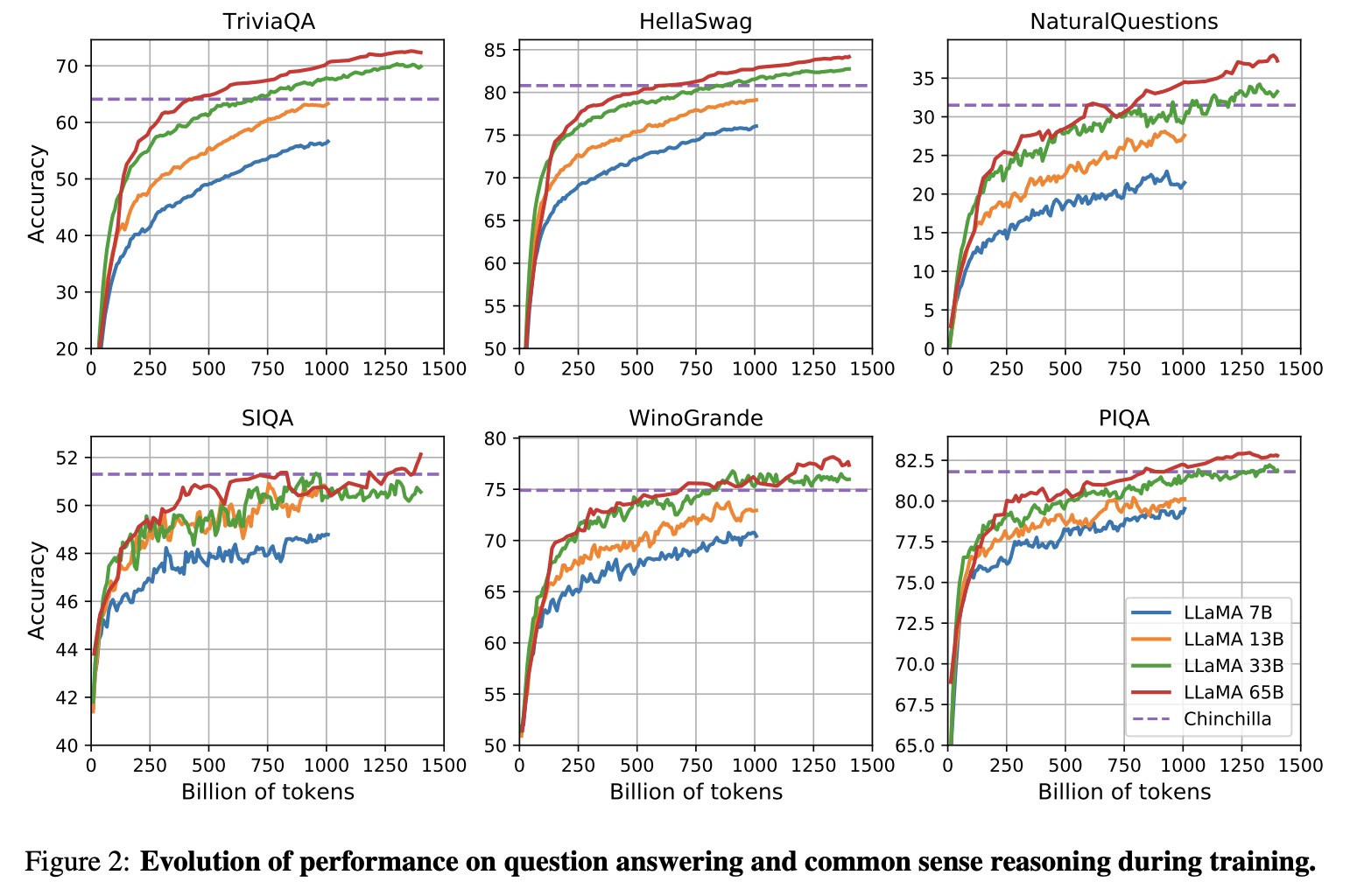
* Common Sense Reasoning: LLaMA-65B outperforms Chinchilla-70B on all reported benchmarks but BoolQ. LLaMA-13B model also outperforms GPT-3 on most benchmarks despite being 10× smaller;
* Closed-book Question Answering: LLaMA-65B achieves state-of-the-art performance in the zero-shot and few-shot settings. LLaMA-13B is also competitive with GPT-3 and Chinchilla, despite being 5-10× smaller;
* Reading Comprehension: LLaMA-65B is competitive with PaLM-540B, LLaMA-13B outperforms GPT-3;
* Mathematical reasoning: On GSM8k, LLaMA65B outperforms Minerva-62B, although it has not been fine-tuned on mathematical data;
* Code generation: LLaMA with 13B parameters and more outperforms LaMDA 137B. LLaMA 65B outperforms PaLM 62B;
* Massive Multitask Language Understanding: LLaMA-65B is behind both Chinchilla70B and PaLM-540B by a few percent in average, and across most domains;
* briefly finetuning on instructions data leads to improvements on MMLU;