[Paper link](https://arxiv.org/abs/2101.07555)

Common approaches use piece boundaries information, but this fails to take into account crucial semantic information. In this paper, the authors offer a self-supervised model with two heads: classification of jigsaw permutations and GAN to generate the image itself. This is a new state-of-the-art.
### The general idea:
The proposed pipeline consists of two branches:
* classification branch predicting the jigsaw permutations
* GAN branch, which recovers features to images with correct sequences
The branches are connected by the encoder and a flow-based warp.
Why do we need this warp? If we take shuffled features and place them in the positions predicted by the classification branch, we won't be able to calculate gradients for backpropagation. Therefore this warp is necessary to move the features into the correct positions.
GAN has the decoder for generating images and the discriminator to decide whether the image is correct.
There are a lot of losses used in this work: edge loss, gan loss, jigsaw loss.
The input data consists of original images, which are cut into n x n pieces and shuffled. The method is called self-supervised because labels for these shuffled images are generated and aren't already given.
The described approach can be used together with other GAN approaches.
Source domain data: shuffled images.
Target domain data: natural images.

### The architecture
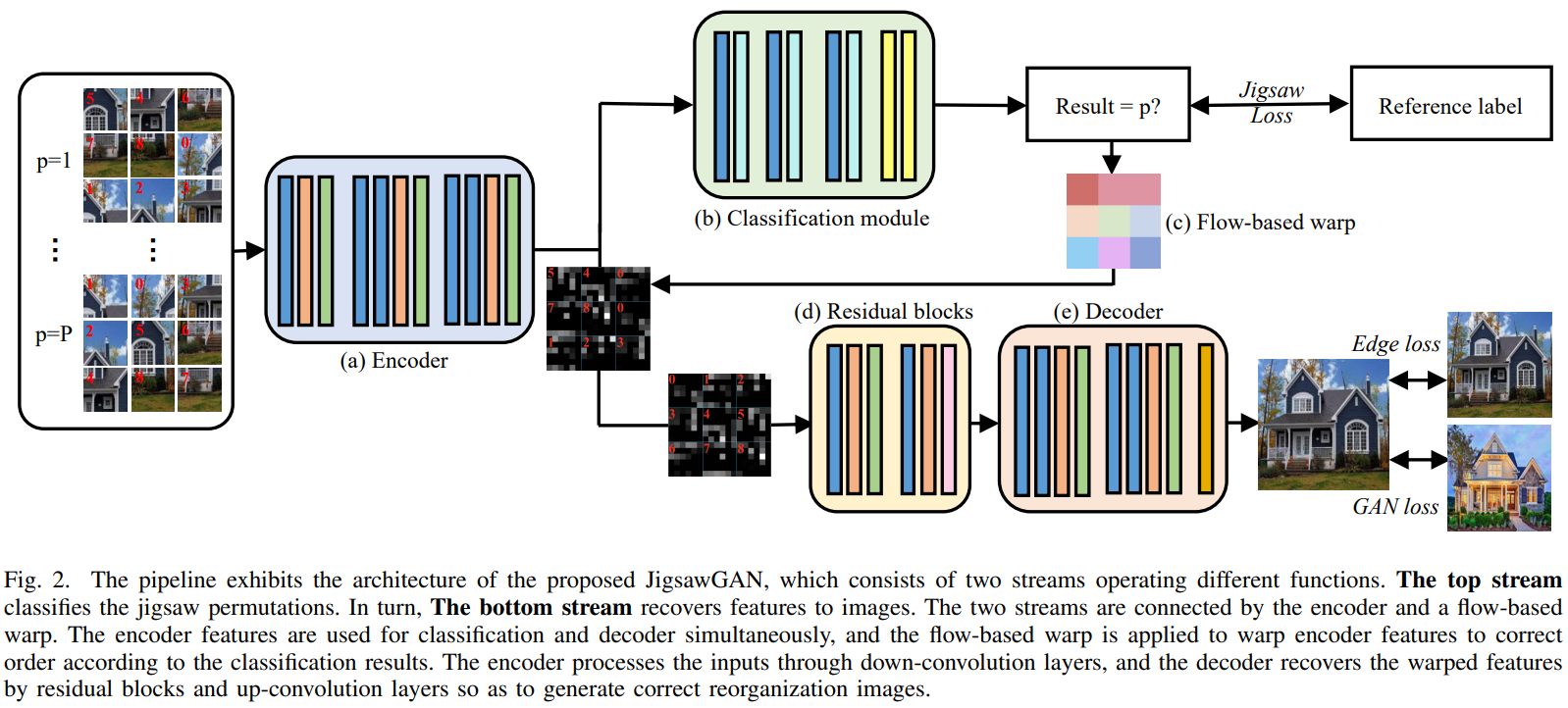
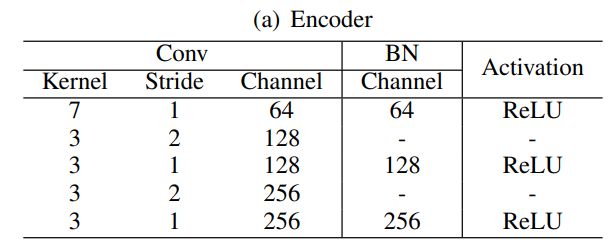
The encoder extracts features from the shuffled images.
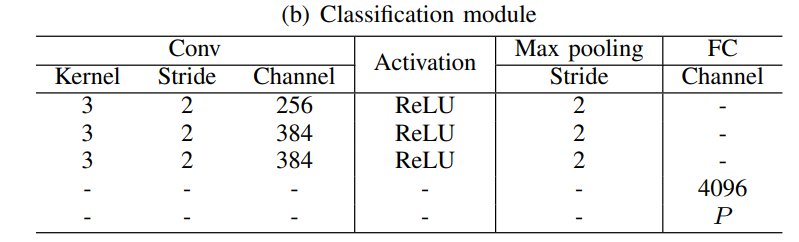
The classification branch predicts jigsaw permutations (the index of the given permutation). Based on this information, the flow-based warp reorders the features.
The generator generates images.
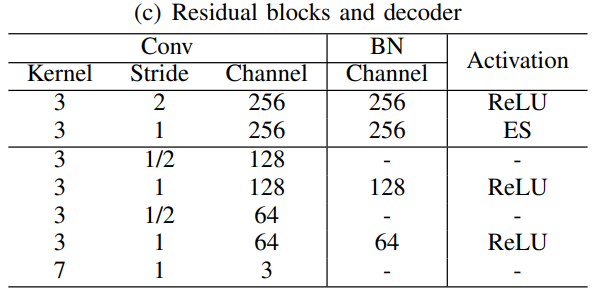
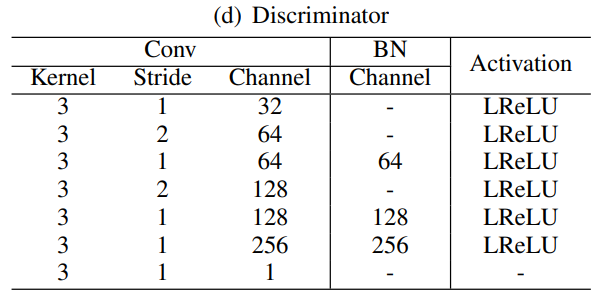
And discriminator makes predictions whether the images are real or fake.
### Loss calculation:
* jigsaw loss: focal loss for permutation classification;
* adversarial loss:
* edge loss: to help make a smooth transition between pieces, especially at the boundaries.
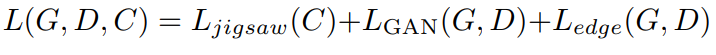
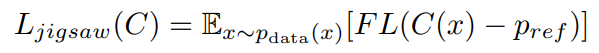
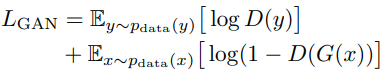
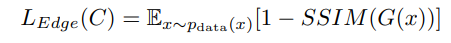
### Experiments:
The authors compare their approach with classical jigsaw puzzle works with DL-based ones and provide an ablation study.
They take the PACS dataset (5156 images) and add 2483 of their own images - they wanted to have more different images in the dataset. There are four categories (house, person, elephant, guitar) and four domains (Photo, Art Paintings, Cartoon, and Sketches).
The input size is 72 x 72, and 1000 permutations are selected. However, the number of permutations and pieces are hyperparameters.
They trained on 2080ti with 100 epochs. Adam with 2x10^-4. Training takes ~4 hours.
Of course, they show nice pictures proving their approach is the best.
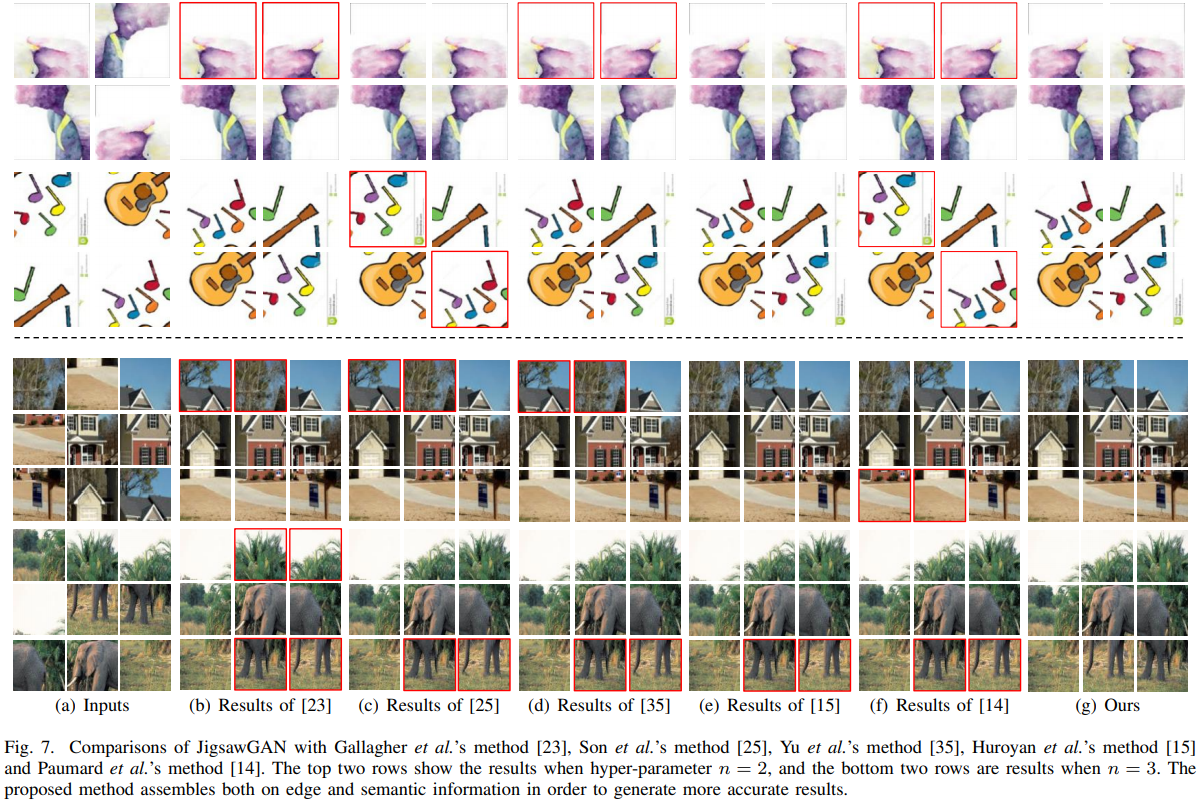
Higher n (more pieces) increases the difficulty of detecting the piece relationship. Higher P (number of classes) makes classification more complicated.