The first Transformer was introduced in the Attention Is All You Need paper, soon after that BERT was published.
This note will cover different ways of building Transformers and how they evolved over time.
Vanilla Transformer
The encoder consists of 6 identical layers, each with two sub-layers: a multi-head self-attention and a position-wise feed-forward network, both followed by residual connections and layer normalization. All outputs are of dimension 512.
The decoder also has 6 similar layers but adds a third sub-layer for multi-head attention over the encoder’s output. It uses the same residual and normalization approach. Additionally, it masks future positions in self-attention to ensure that predictions for the next position only depend on earlier positions.
Variations
Tokenizers
| Tokenizer | Description |
|---|---|
| BPE | Byte-Pair Encoding. Merges the most frequent pairs of characters or subwords iteratively; words are split into the longest known subword pieces. Examples: GPT-2, RoBERTa. |
| WordPiece | Optimized BPE — matches longest substrings from the start. Examples: BERT. |
| SentencePiece | Examples: T5, ALBERT. |
Positional embeddings
Positional embeddings are added to the token embeddings. Optionally, segment embeddings can be added too — in BERT, segment embeddings separate pairs of sentences.
| Type | Description |
|---|---|
| Sinusoidal | Fixed. Extends for longer sequences but usually works worse than learnable embeddings. |
| Learned absolute | Per-position vector; max length fixed at training time. Added inside the attention mechanism. |
| Relative | Encodes distance between tokens (e.g., B is N steps ahead of A). |
| T5 bias | Learns a scalar bias added directly to the attention logits based on the relative distance between query and key. |
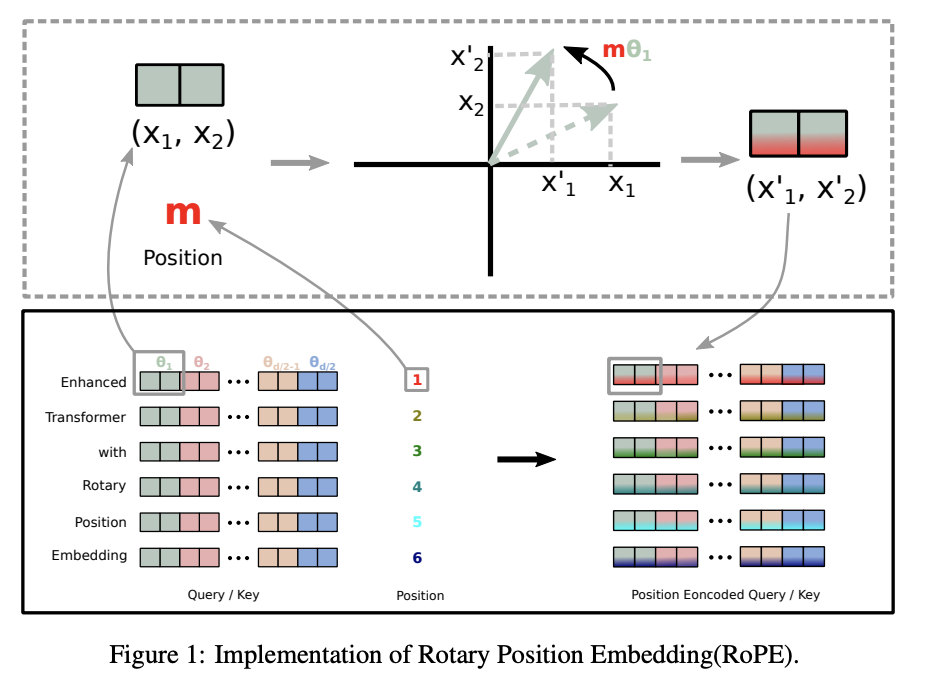
| RoPE | Rotary Positional Embeddings. Position-dependent rotations applied to chunks of Q/K vectors before the dot product. |
Decoding strategies
| Strategy | Description |
|---|---|
| Greedy search | At each step, pick the single token with the highest probability. Simple and deterministic; prone to repetition and bland output. Locally optimal choices can lead to a poor overall sequence. |
| Beam search | Maintain parallel candidate sequences (“beams”); at each step expand each beam and keep the top by cumulative log-probability. Produces more coherent text than greedy, but can still repeat. |
| Temperature sampling | Rescale logits by before softmax — . increases randomness, decreases it; approaches greedy. Higher is useful for creative generation. |
| Top-K sampling | At each step, consider only the most probable tokens. Cheap way to cut off unrealistic tail choices. |
| Top-P (nucleus) sampling | Select the smallest set of tokens whose cumulative probability exceeds . More adaptive than Top-K across contexts with different entropy. |
Notable architectures
| Model | Description |
|---|---|
| ALBERT | A Lite BERT. Factorized embedding parameterization (splits the vocabulary embedding matrix into two smaller matrices), cross-layer parameter sharing, inter-sentence coherence loss. |
| Alpaca | LLaMA fine-tuned on ~52k synthetic instruction-following examples. |
| BART | Bidirectional and Auto-Regressive Transformers. BERT’s bidirectional encoder paired with GPT’s autoregressive decoder. |
| CLIP | Contrastive Language-Image Pre-training. Dual-encoder (ViT or ResNet image encoder + Transformer text encoder) trained contrastively on image-text pairs. |
| DALL-E | Text-to-image generation. V1 uses a discrete VAE to tokenize images and an autoregressive Transformer over the joint distribution of text and image tokens. |
| DeBERTa | Decoding-enhanced BERT with disentangled attention. Disentangled attention and a mask decoder enriched with absolute word-position information. |
| ELECTRA | A small generator (like a small BERT) replaces tokens via MLM; the larger discriminator (the main ELECTRA model) predicts whether each token is original or was replaced. |
| LLaMA | Decoder-only with pre-normalization (RMSNorm), SwiGLU, and RoPE. |
| Mistral | Efficient decoder-only model with Grouped-Query Attention (GQA) and Sliding Window Attention (SWA). |
| RoBERTa | Optimized BERT — more data, no NSP, dynamic masking, larger byte-level BPE vocabulary. |
| T5 | Text-to-Text Transfer Transformer. Encoder-decoder pre-trained on a span-corruption objective. |
| XLNet | Permutation language modeling. |
| RWKV | Linear time like RNNs; performs like Transformers. |
| Mamba | State-space model — linear scaling in sequence length. |
Various information
- Encoder-only, encoder-decoder, and decoder-only models:
- Encoder-only: good for encoding input into a rich representation; often used for sentence classification, NER, QA classification, embedding generation. Usually trained with MLM. Examples: BERT.
- Decoder-only: good for generation; often used for text/code completion, dialogues, language modeling. Usually trained with Causal Language Modeling. Examples: GPT, LLaMA, Mistral.
- Encoder-decoder (or seq2seq): good for text transformation; often used for machine translation, summarization, QA generation, image captioning. Usually trained with seq2seq objectives. Examples: T5, BART.
- Layer Normalization (LayerNorm): normalizes samples across the feature dimension instead of normalizing features across batches (like in Batch Normalization). It normalizes by mean and variance with two learnable parameters: . In the standard Transformer it was applied after multi-head attention and dense sub-layer; currently, pre-normalization — before multi-head attention and dense sub-layer — is more widely used.