Recurrent Neural Networks are a type of neural networks designed for processing sequential data. Unlike feedforward networks, RNNs have connections that form directed cycles, allowing them to maintain an internal state that captures information about previous inputs in a sequence.
The core idea behind RNNs is to process sequential data one element at a time while maintaining information about previous elements through a hidden state.
graph LR A[Input x<sub>t</sub>] --> B((RNN Cell)) C[Hidden State h<sub>t-1</sub>] --> B B --> D[Output y<sub>t</sub>] B --> E[Hidden State h<sub>t</sub>] E --> F[Next Timestep]
RNN Architecture
At each time step t, a basic RNN cell:
- Takes the current input and previous hidden state
- Computes a new hidden state
- Produces an output
The mathematical formulation:

RNN Variants
- Bidirectional RNN processes sequences in both forward and backward directions to capture context from both past and future states.
- Deep (Stacked) RNN stacks multiple RNN layers on top of each other, with the output sequence of one layer forming the input sequence for the next.
Common Problems
- Standard RNNs suffer from vanishing or exploding gradients during backpropagation through time, making them difficult to train on long sequences. The possible solutions are: gradient clipping, better weight initialization, specialized architectures like LSTM and GRU
- Standard RNNs struggle to capture long-range dependencies in sequences.
LSTM Architecture
LSTMs solve the vanishing gradient problem by introducing a cell state and three gates:
Input Gate: Controls what new information to store
Forget Gate: Controls what information to discard
Output Gate: Controls what information to output

Mathematical formulation:
GRU Architecture
GRUs are a simplified variant of LSTMs with fewer parameters.
Update Gate: Combines input and forget gates
Reset Gate: Controls how much of previous state to forget
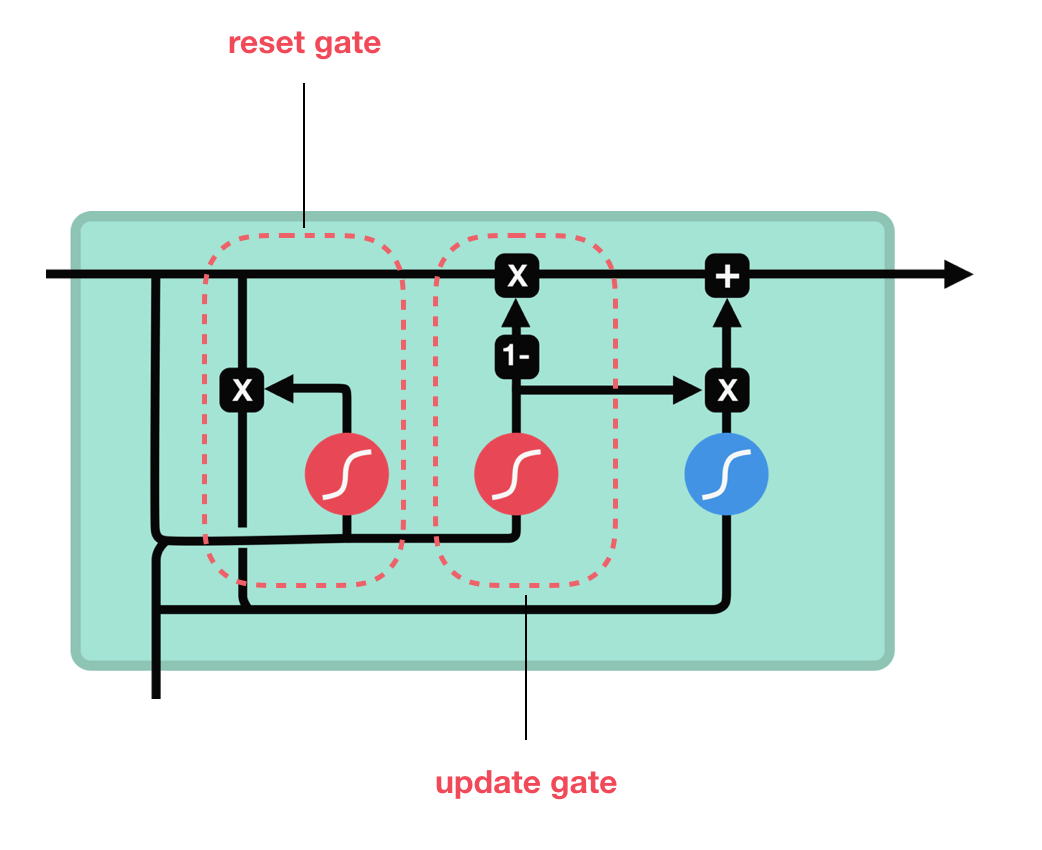
Mathematical formulation: