Retrieval-Augmented Generation (RAG) is a hybrid approach that combines LLM’s generative abilities with real-time information retrieval from external knowledge sources. RAG enhances LLMs by first retrieving relevant information from a knowledge base or corpus, then using this information to augment the context provided to the generative model before generating the final response.
RAG is designed to mutigate multiple limitations of LLM: improving factual accuracy, providing source attribution, mitigating knowledge cutoff issues, and reducing hallucinations.
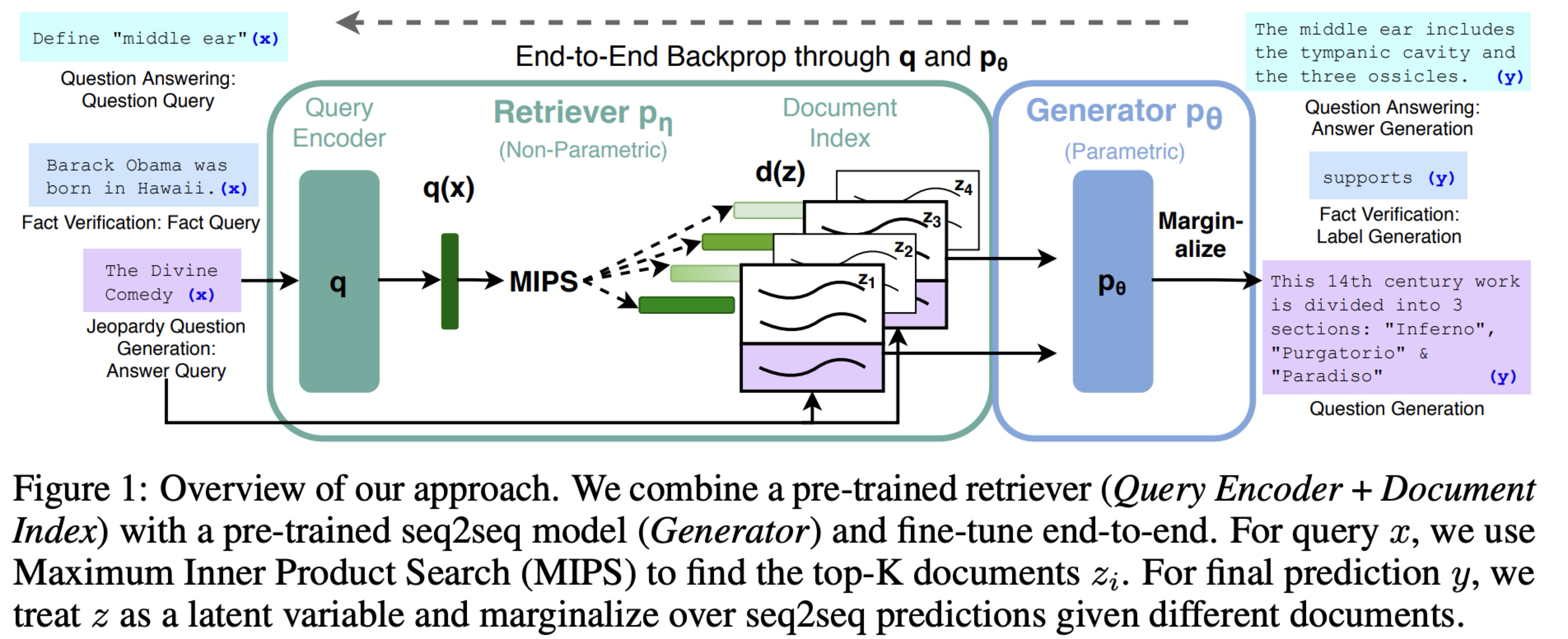
The original RAG paper used a pre-trained retriever to fetch relevant documents and a sequence-to-sequence model to generate outputs conditioned on both the query and retrieved documents.
Generally speaking, developing a RAG system involves creating two separate processes: preparing the documents (indexing) and querying them (retrieval and generation).
Indexing (Offline Data Preparation)
This phase prepares the external knowledge base so that relevant information can be efficiently retrieved later. It typically includes the following steps:
- Data Loading: Identifying and loading the source documents. These can come from various sources like document files, databases, APIs, collaboration platforms, etc. Different sources may require different approaches to loading and updating.
- Data Cleaning & Preprocessing: Cleaning the loaded data by removing irrelevant content, correcting errors, and standardizing formats.
- Document Chunking (Splitting): Breaking down large documents into smaller, manageable chunks. This is crucial because LLMs have limited context windows, and retrieval works better on focused pieces of text. Each chunk may have metadata (source document, creation date, summaries, tags, keywords, structural information). Each chunk should ideally be self-contained enough to make sense but small enough for effective retrieval and context fitting. Common strategies:
- Fixed-size chunking: Splitting text into chunks of a fixed number of characters or tokens, possibly with overlap to maintain context continuity between chunks.
- Content-aware chunking: Splitting based on semantic boundaries (paragraphs, sections, sentences using). Recursive character splitting is a common technique.
- Hierarchical chunking: Maintaining parent-child relationships between chunks (e.g., section → paragraph → sentence) can help retrieve context at different granularities.
- Agentic chunking: Using an LLM to determine the optimal way to chunk documents based on their content and structure.
- Embedding Generation: Using an embedding model to convert each text chunk into an embedding. Embedding models can be fine-tuned on domain-specific data for better relevance. It is possible to use multiple embedding models or represent a single chunk with multiple vectors (for example, a a separate vector per paragraph, or separate vectors for title and content).
- Indexing: Storing the text chunks and their corresponding embeddings in an efficient index, usually a Vector Database (Pinecone, Weaviate, , Chroma, FAISS, Milvus, Qdrant). This allows to do fast similarity searches based on vector proximity. Metadata is typically stored alongside the embeddings to enable filtering before or after the vector search.
Retrieval and Generation (Online/Runtime Query)
When a user submits a query, the system retrieves relevant information and generates an answer. This phase typically involves:
- Query Formulation/Transformation: The user’s input query might be ambiguous or lack context. Refining the query can produce better retrieval results. Possible approaches:
- Query Expansion: Adding synonyms, related terms, context from the conversation.
- Query Transformation: Rephrasing the query, potentially using an LLM (Hypothetical Document Embeddings (HyDE), Step-Back Prompting, contextual retrieval).
- Sub-Query Generation: Breaking down a complex query into multiple simpler queries whose results can be aggregated.
- Metadata extraction: Extracting relevant metadata similar to the one that was extracted during data preparation.
- Query classification and routing: Directing queries to specialized retrievers or knowledge bases based on the query type (e.g., keyword search for specific terms, vector search for semantic meaning).
- Query Embedding: The query is converted into an embedding using the same embedding model used during the indexing.
- Search (Retrieval): The query embedding is used to search the vector index. The system retrieves the k most similar document chunks (the “top-k” results) based on a chosen similarity metric (cosine similarity, dot product, Euclidean distance). In may include:
- Hybrid Search: Combining vector search with traditional keyword search (like BM25).
- Metadata Filtering: Filtering chunks based on attached metadata before or after the vector search.
- Domain Adaptation/Fine-tuning: Retrieval models (embedding models) can be fine-tuned using contrastive learning on domain-specific query-document pairs to improve relevance.
- Knowledge graphs can be used to improve retrieval.
- Re-ranking: The re-ranking step can improve precision by using a better model (cross-encoder or LLM) to re-order the top-k chunks. Diversity-aware ranking can also be applied here to ensure the final context isn’t too redundant. Another approach is multi-stage retrieval (retrieve many → cluster → rerank within clusters → select top from each).
- Context Augmentation and Prompt Engineering: The original user query and the final set of retrieved (and re-ranked) text chunks are combined into a single prompt for the LLM. The prompt often includes explicit instructions for the LLM to ensure it separates the query and the retrieved context, uses only the retrieved information, produced the output in the desired format, etc.
- Generation: The augmented prompt is fed to the LLM, which generates the final response. The LLM synthesizes the information from the retrieved context to answer the user’s query, ideally grounding its answer in the provided snippets. Generator model can be fine-tuned using instruction fine-tuning on RAG tasks; PEFT (for efficiency), RL.
- Post-processing: Filtering redundant information, moderation to remove harmful content, citation addition.
Additional improvements/variations
- Caching results for common queries
- Multi-model RAG to work with images, audio, video.
- Multi-hop RAG (Iterative Retrieval) breaks down a query into sub-queries or performs multiple rounds of retrieval and generation. It may retrieve an initial context, use the LLM to generate a follow-up query based on that context, retrieve again, and so on, chaining evidence. This mimics how a human might answer a complex question by gathering facts step-by-step. In practice, this is implemented via query decomposition and chained retrieval, then having the LLM synthesize a final answer from all the gathered chunks. This is especially useful, when the query answering requires information from multiple documents.
- Having router models after the query and having different models for different query types/domains
- It is possible to use any techniques applicable to generation in general - SelfRAG for self-reflection, chain-of-thought, Agentic Retrieval-Augmented Generation for Time Series Analysis with agents, etc
- Late-chunking: embed the entire document, then chunk the embeddings - a long context embedding model creates token embeddings for every token, then they are broken up and pooled into chunk embeddings.
- RankRAG uses a single LLM to both rank contexts and generate answers by incorporating a small amount of ranking data into the training.
Evaluation
-
Retrieval Performance:
- Precision@k: Proportion of retrieved documents that are relevant
- Recall@k: Proportion of all relevant documents that were retrieved
- Mean Average Precision (MAP): Average precision across multiple queries
- NDCG (Normalized Discounted Cumulative Gain): Measures ranking quality considering relevance and position
- Mean Reciprocal Rank (MRR): Average of reciprocal ranks of the first relevant document
-
Generation Performance (Conditional on Retrieval):
- Factual Consistency: Measures whether generated text is consistent with retrieved context
- ROUGE/BLEU/METEOR: Traditional text generation metrics
- BERTScore/BLEURT: Semantic similarity metrics
- QA-based metrics: Using QA models to verify factual claims in generated text
-
End-to-End Performance:
- RAGAS: A framework for evaluating RAG systems on Faithfulness, Context relevance, Answer relevance.
- Knowledge Conflicts: How well the system handles conflicting information in retrieved documents
- Human Evaluation