LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique that allows to adapt large pre-trained models to specific tasks while minimizing computational resources.
Core Concept
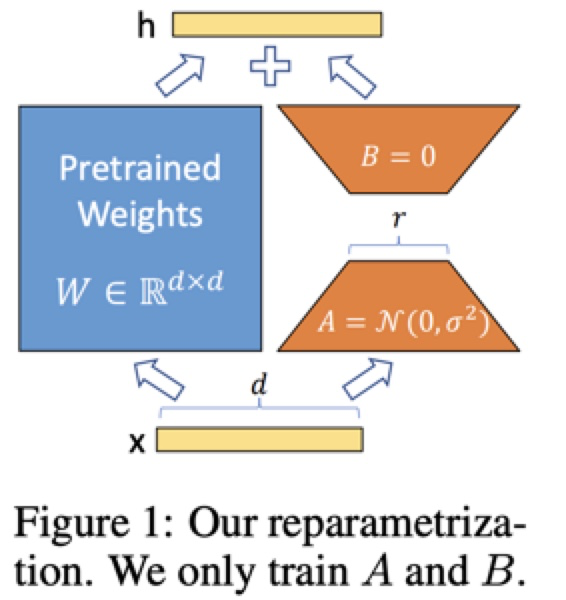
While pre-trained models have large weight matrices, the rank of the update matrices (changes) during fine-tuning can be much lower. LoRA does the following:
- Freezes the original pre-trained model weights
- Injects trainable low-rank decomposition matrices into model layers
- Represents weight updates as the product of these smaller matrices
Mathematically, instead of directly learning a weight update matrix to add to the pre-trained weight matrix W, LoRA approximates this update using two smaller matrices:
Where:
- A is a matrix of size r × d (r << d)
- B is a matrix of size d × r (r << d)
- r is the rank parameter (typically 4-256)
During inference, the effective weight matrix becomes:
LoRA is typically applied to selected weight matrices within transformer architectures:
- Most commonly applied to attention layers (query, key, value, and output projection)
- Can also be applied to feed-forward network layers
- Usually initialized with A using random Gaussian initialization and B with zeros
An additional scaling parameter α is used to control the magnitude of updates:
Advantages
- Parameter Efficiency: Reduces trainable parameters by up to 10,000 times compared to full fine-tuning for LLMs.
- Memory Efficiency: Reduces GPU memory requirements by approximately 3 times compared to full fine-tuning.
- No Inference Latency: LoRA matrices can be merged with the original weights after training, resulting in no additional latency during inference.
- Comparable or Better Performance: Often performs on par with or better than full fine-tuning despite having fewer trainable parameters.
- Task Switching: Makes it easier to switch between different tasks by swapping only the LoRA weights instead of entire model checkpoints.
Key Hyperparameters
- Rank (r): Controls the capacity of the adaptation. Higher ranks provide more flexibility but increase parameter count. Usual values are 4-256, but after 64 or 128 there are diminishing returns. For smaller models
rcan be lower, for larger models it should be large. - Alpha (α): Scaling factor for the LoRA updates. A good heuristic is to set alpha to twice the rank value.
- Target Modules: Which layers of the model to apply LoRA to. Applying LoRA to more layers generally improves performance but increases memory usage.
- Dropout: Can be applied to LoRA matrices to prevent overfitting.
Variants
- QLoRA: Quantizes the base model to 4-bit precision to further reduce memory requirements.
- Layer-wise Optimal Rank Adaptation: Assigns different ranks to different layers based on their importance.
- AdaLoRA: Adaptively allocates parameter budget across layers.
- VeRA: Vector-based Random Matrix Adaptation, where the low-rank decomposition uses random matrices.